퍼징의 기초 - Code Coverage의 이해
2006년 블랙햇에서 Shawn Embleton 등은 Sidewinder 발표를 통해서 코드 커버리지에 기반한 퍼징 방법론에 대해서 발표합니다. 이후 2008년 Fuzz By Number라는 발표에서 찰리 밀러는 더 많은 코드 커버리지를 커버하는 샘플 셋을 가질 때에 덤 퍼징 조차도 더 효율적으로 진행된다라는 실험 결과를 내어 놓습니다. 이후 Code Coverage의 개념은 퍼징에 있어서 굉장히 중요한 개념으로 자리잡게 됩니다. 이 아티클을 통해서 이러한 퍼징의 기초 개념중에 코드 커버리지의 개념에 집중해서 대해서 알아 보겠습니다.
2000년대 들어 많은 취약점 문제를 안고 있던 마이크로소프트 등의 회사에서는 SAGE 등의 컨셉에 기반한 Code Coverage Guided Fuzzing의 개념을 일찍부터 사용하여 프러덕 시큐리티에 적용하고 있었습니다. 이후 마이크로소프트사는 이 서비스를 클라우드 형태의 Microsoft Security Risk Detection이라는 서비스로 공개합니다. 이후 최근에는 대표적으로 AFL과 같은 퍼징 프레임워크의 발표와 함께 함께 리서쳐들도 Code Coverage Guided Fuzzing을 손쉽게 접할 수 있게 됩니다. 오리지날 AFL은 Compile-based Instrumentation을 사용하고 있어서, 윈도우즈 환경에서는 WinAFL과 같이 DynamoRIO나 IntelPT와 같은 기술을 적용한 프로그램을 사용하여야 합니다. 이후 AFL을 필두로 libFuzzer, Honggfuzz 아니면 커널 IOCTL들에 대한 퍼저인 Syzkaller 등의 다양한 Code Coverage Guided Fuzzer 들이 개발되고 있습니다.
일반적인 Code Coverage Guided Fuzzer 구조
AFL 등을 비롯한 대부분의 Code Coverage Guided Fuzzer 들은 다음과 같은 구조로 작동됩니다.
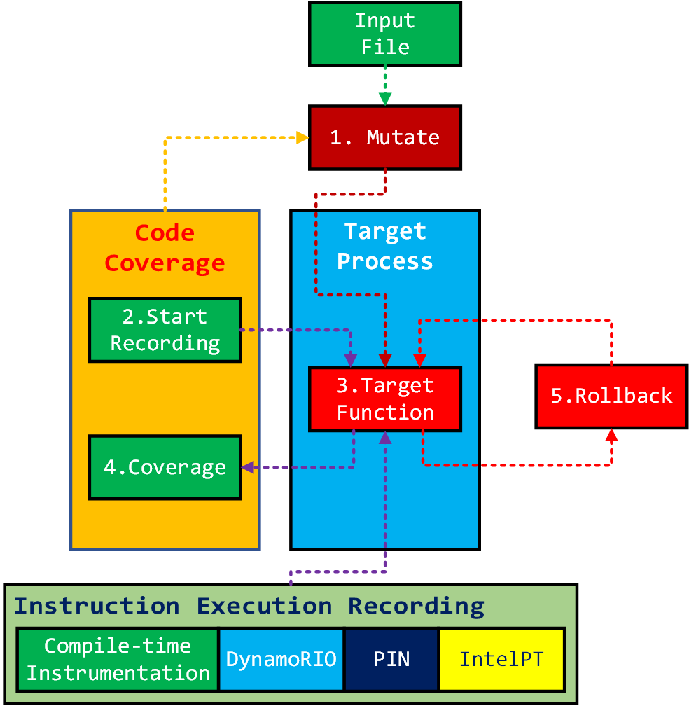
- Mutate: 먼저 input 파일들에 대한 mutation 과정을 거칩니다.
- Start Recording: 해당 파일을 파싱하는 코드에 대한 코드 커버리지 레코딩을 시작합니다
- Target Function: 타겟이 되는 함수가 실행됩니다.
- Coverage: 해당 타겟이 되는 함수의 코드 커버러지 데이타가 컬렉트됩니다.
- Rollback: 해당 함수를 롤백하고 위의 1번 과정을 코드 커버리지 데이타에 기반해서 다시 시행합니다.
이 과정에서 mutation 알고리즘은 코드 커버리지 데이타를 피드백으로 받아서 새로운 코드 커버리지를 찾아 내는 형태로 계속 발전 시키는 방향으로 진행됩니다.
일반적인 퍼징의 과정
이러한 코드 커버리지에 기반한 퍼징을 실행하기 위해서는 다음 다이어그램에서 보듯이 덤 퍼징에 비해서 생각보다 복잡한 과정을 거칩니다.
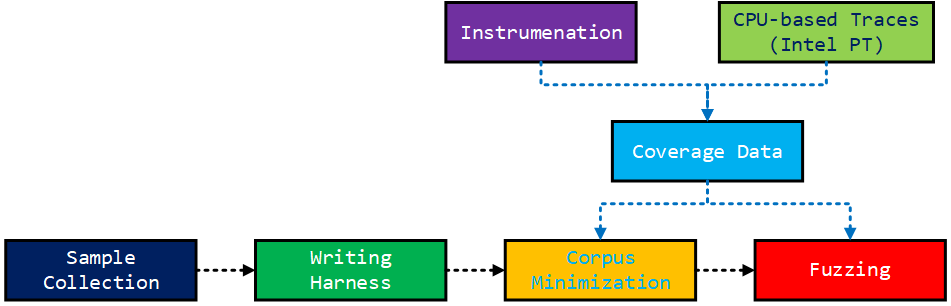
먼저 샘플 컬렉션 과정을 거칩니다. 이후 이러한 샘플들의 파싱 코드가 존재하는 함수들을 아우르는 엔트리 포인트를 잡아서 harness 함수를 작성해 주어야 합니다. 많은 경우 파서가 라이브러리나 DLL 형태로 존재한다면 어떠한 함수를 써서 해당 파싱 코드를 trigger할 수 있는지에 대한 조사 단계가 필요합니다.
Corpus Minimization
이렇게 harness까지 작성이 되면, 컬렉션된 샘플셋에 대해서 Corpus Minimization이라는 과정을 거쳐야 합니다.
Corpus는 흔하게 잘 사용되지 않는 영어 단어로서 구글 서치에 의하면, 다음과 같은 의미를 가집니다.
- a collection of written texts, especially the entire works of a particular author or a body of writing on a particular subject.
Corpus는 쉽게 말해서 어떠한 저자의 모든 저작물들을 통칭하는 용어입니다. 퍼징에 있어서 Corpus는 간단하게 말해서 퍼징에 사용되는 샘플셋을 의미한다고 생각하면 됩니다.
예를 들어 WinAFL에서는 winafl-cmin.py과 같은 툴을 제공합니다. 이러한 툴을 통해서 코드 커버리지가 최대한 겹치지 않는 최소한의 샘플 셋을 만들어 퍼징 효율을 높일 수 있습니다. 이 툴은 afl-showmap 유틸리티를 활용하여 AFL이 내어 놓는 trace bitmap 컬렉션이 최대한 겹치지 않는 샘플셋으로 최적화를 진행해 줍니다.
Coverage Data
이러한 Corpus Minimization이나 mutation 과정에 절대적으로 필요한 것이 Coverage Data입니다. 소스 코드 확보가 가능한 경우에는 LLVM 등을 사용하여 compile-time instrumentation을 사용할 수 있습니다. 윈도우즈 바이너리들과 같이 소스 코드가 없는 경우 다음과 같은 바이너리 인스트루멘테이션 툴이나 Intel PT (Processor Trace)와 같은 CPU 기능을 사용하게 됩니다. Intel PT는 Intel Skylake CPU 이상에서 사용 가능한 인스트럭션 트레이싱 기술입니다.
- Dynamic instrumentation using DynamoRIO
- Hardware tracing using Intel PT
- Static instrumentation via Syzygy
Lighthouse
이러한 코드 커버리지는 winafl-cmin.py 등으로 corpus minimization하는 데에 필요하지만, 많은 경우 실제로 어떠한 샘플이 자신이 원하는 함수들을 커버하고 있는지 수동적으로 확인해 볼 필요성들이 생깁니다. 이 경우 사용할 수 있는 툴이 lighthouse라는 IDA 플러그인입니다. 이 플러그인을 사용하면, Coverage Data를 사람이 직접 확인할 수 있게 되어 효율적인 샘플 확보와 퍼징의 여러 트러블 슈팅 등이 편리해 집니다. Lighthouse는 IDA와 BinaryNinja를 지원합니다.
Lighthouse는 DynamoRIO나 PIN, Frida와 같은 툴의 아웃풋으로 커버리지 데이타를 뽑을 수 있게 해줍니다.
- 예를 들어 DynamoRIO로는 다음과 같은 coverage 파일을 생성하여 lighthouse로 로딩하는 것이 가능합니다.
..\DynamoRIO-Windows-7.0.0-RC1\bin64\drrun.exe -t drcov -- boombox.exe
- PINTool에서도 다음과 같이 커버리지를 생성하는 툴을 제공합니다.
pin.exe -t CodeCoverage64.dll -- boombox.exe
- Frida의 경우 frida-drcov.py과 같은 스크립트를 활용할 수 있습니다.
Intel PT와 lighthouse: IPTAnalyzer
Intel PT는 퍼징에 있어서 코드 커버리지를 제공하기 위한 굉장히 좋은 소스이면서도 이해하기 어려운 테크놀로지 중의 하나입니다. 가장 큰 문제는 Intel PT에 의해서 생성되는 트레이스 파일을 해석하는데에 많은 시간이 걸리고, 데이타를 해석하는데에 많은 혼란이 있기 때문입니다.
다음과 같이 Intel PT의 여러 패킷들은 모든 인스트럭션의 주소를 저장하는 것이 아니라, 실행되는 바이너리의 정적 분석을 통해서 컨트롤 플로우를 알 수 없는 경우에만 레코딩을 시행합니다.
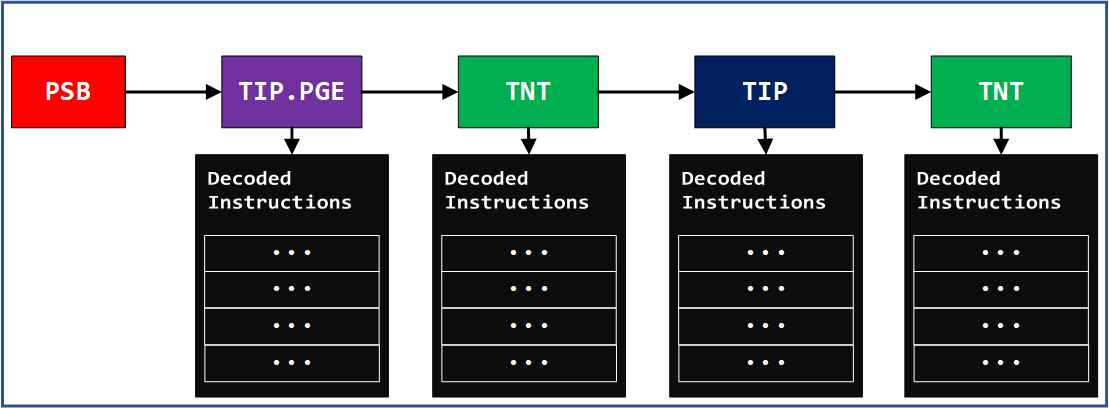
이러한 이유로 Intel PT 트레이스를 해석하기 위해서는 원본 바이너리의 이미지를 제공하여 주어야 합니다.
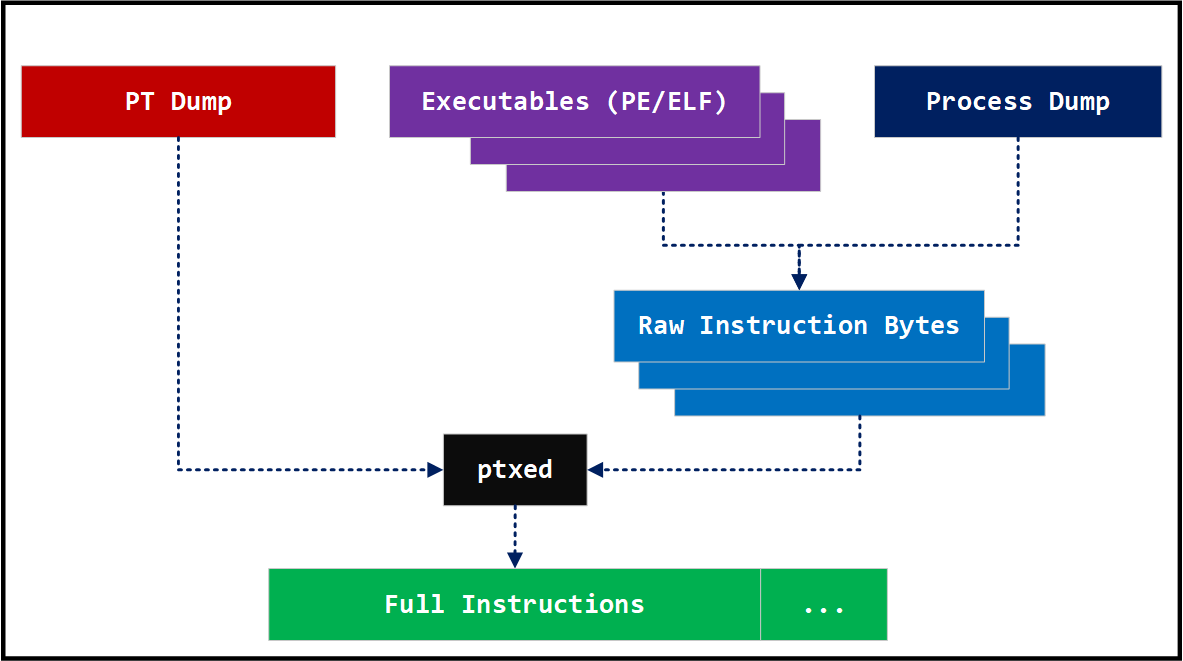
다른그림에서 오픈소스로 공개한 IPTAnalyzer는 인텔의 libipt 라이브러리를 활용하여 Intel PT 로그를 멀티프로세싱 모듈로 병렬 처리하여 SQLite 형태의 블락 트레이스 캐쉬 파일로 변환해 주는 툴입니다. 또한 개개의 바이너리를 수동으로 가공하여 입력하는 대신, 프로세스 덤프 파일을 자동으로 파싱하여 해당 이미지에서의 인스트럭션들을 재구성해 냅니다. 이러한 과정을 통해서 생성된 SQLite 형태의 캐쉬 파일을 통해서 lighthouse에서 로딩 가능한 형태의 커버리지 데이타를 뽑아 내는 것도 가능합니다. IPTAnalyzer를 이용한 취약점 triage 에 대해서는 다른그림의 영문 블로그인 Using Intel PT for Vulnerability Triaging with IPTAnalyzer를 참조하시기 바랍니다.
IPTAnalyzer를 사용하여 캐쉬를 생성하는 것은 다음과 같은 과정을 거칩니다. 윈도우즈의 경우 %IPTANALYZER% 변수를 iptanalyzer가 인스톨 된 폴더로 세팅합니다. 이 실행 예제의 데이타 파일들은 IPTAnalyzer-CVE-2017-11882 폴더에서 다운로드 받을 수 있습니다.
python %IPTANALYZER%\pyipttool\generate_cache.py -p artifacts\EQNEDT32.pt -d artifacts\EQNEDT32.dmp -o artifacts\blocks.sqlite -D 0
각 명령어 옵션은 다음과 같습니다.
- -p: Intel PT 트레이 파일
- -d: 프로세스 덤프 파일
- -o: 블락 정보를 저장할 캐쉬 파일 (sqlite 포맷)
- -D: 디버그 레벨
약간의 시간후에 캐쉬 파일인 artifacts\blocks.sqlite 파일이 생성되면, 이 파일에서 코드 커버리지 데이타를 뽑아 낼 수 있습니다.
python %IPTANALYZER%\pyipttool\dump_coverage.py -p artifacts\EQNEDT32.pt -d artifacts\EQNEDT32.dmp -C 0 -c artifacts\blocks.sqlite -m EQNEDT32 -o coverage.txt
각 명령어 옵션은 다음과 같습니다.
- -p: Intel PT 트레이스 파일
- -d: 프로세스 덤프 파일
- -c: 블락 정보가 저장된 캐쉬 파일 (sqlite format)
- -m: 코드 커버리지 정보를 뽑아 낼 모듈 이름
- -D: 디버그 레벨
- -o: 아웃풋 커버리지 파일
이 명령을 통해서 최신 버전의 Lighthouse에서 지원하는 Module + Offset (modoff) 형태의 coverage 파일이 생성됩니다.
해당 파일은 다음과 같은 간단하면서도 이해하기 쉬운 포맷을 가지고 있습니다.
EQNEDT32+32c6
EQNEDT32+32c7
EQNEDT32+32c9
EQNEDT32+32ca
EQNEDT32+32cb
EQNEDT32+32cc
EQNEDT32+32cd
EQNEDT32+32ce
EQNEDT32+32cf
EQNEDT32+32d0
EQNEDT32+36d7
EQNEDT32+36d8
EQNEDT32+36da
EQNEDT32+36db
EQNEDT32+36dc
EQNEDT32+36dd
...
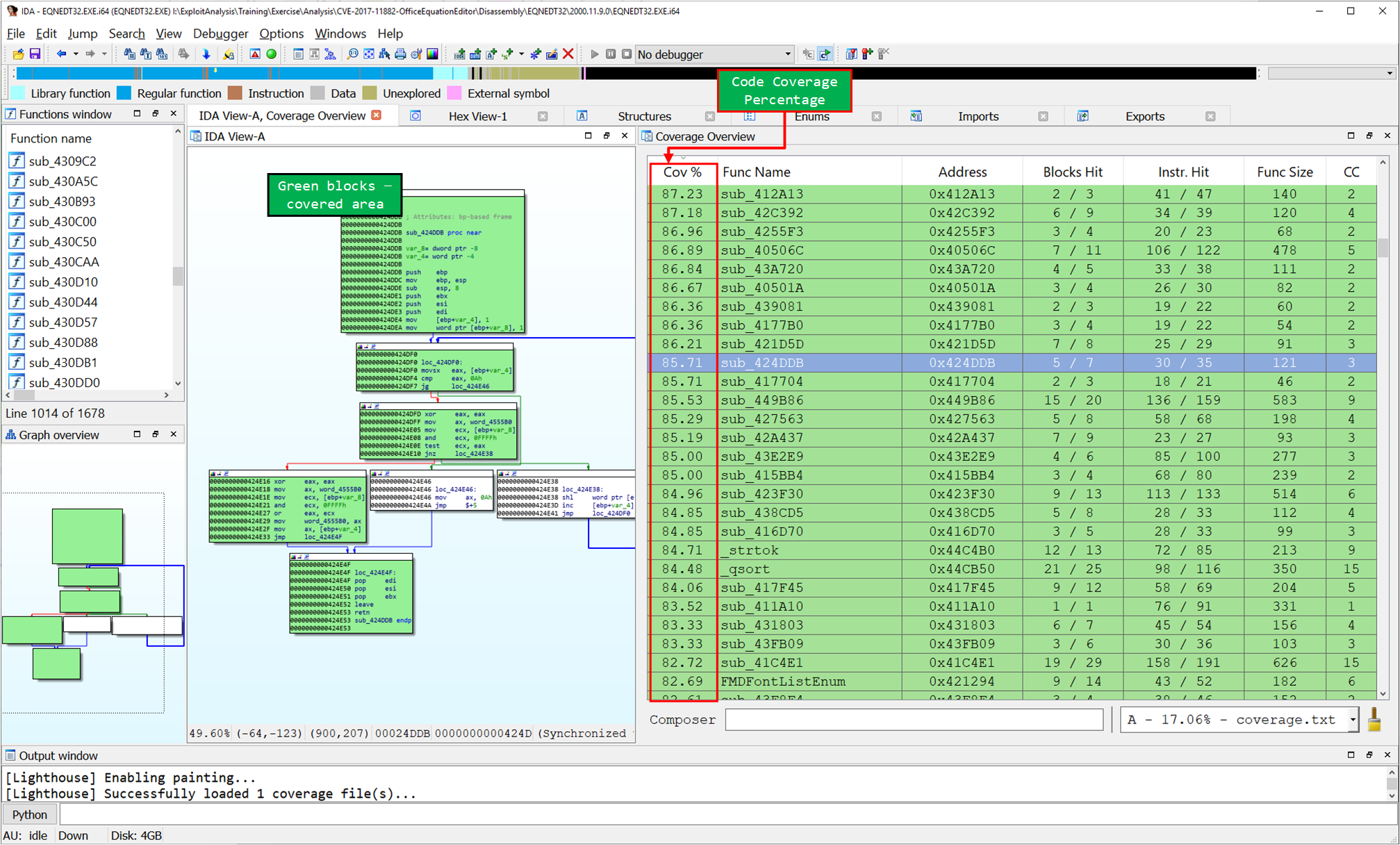
이 데이타를 lighthouse 플러그인으로 로딩하면 다음과 같은 코드 커버리지 리스트와 맵을 얻을 수 있습니다. 이로서 특정 샘플이 특정 바이너리에서 어떠한 코드 커버리지를 가지고 있는지 IDA를 통해서 디버깅해 볼 수 있게 되었습니다.
결론
Intel PT는 kAFL과 같은 커널 퍼징 등에도 많이 이용되고 있습니다. 다만, Intel PT의 고강도 압축 알고리즘으로 인해서 이후 트레이스 압축 해제나 해석 부분에서 많은 버그나 속도 문제가 발생하는 경우가 많습니다. Intel PT를 퍼징에 더 광범위하게 활용하기 위한 첫번째 단계로 Lighthouse에 Intel PT의 트레이스 로그로부터 추출한 커버리지 데이타를 로딩하는 실험을 해 보았습니다. 다음 아티클에서는 이러한 데이타를 이용하여 어떻게 Corpus Minimization 전략을 수립할지에 대해서 논의해 보겠습니다.
트레이닝 정보
다른그림에서는 윈도우즈 플랫폼 하에서 버그 헌팅 전문가와의 코워크를 통해서 퍼징에 관한 중급 트레이닝 과정을 개설하고 있습니다. 관심 있으신분은 jeongoh@darungrim.com으로 문의 주시면 감사하겠습니다.